
Perkembangan teknologi informasi saat ini sangat membantu dalam bisnis perusahaan. Namun demikian kalau kita tidak paham tipe teknologi yang dibutuhkan bisa saja kita akan salah memilih teknologi. Khususnya dalam bidang pengambilan keputusan untuk perusahaan terdapat salah satu produk teknologi informasi yang sangat membantu, yaitu sistem pendukung keputusan.
Usaha universitas STEKOM untuk memiliki jangkauan global diantarnya dengan mengadakan webinar dalam skala internasional. Pada kesempatan kali ini kita akan membahas sebuah webinar internasional yang diadakan oleh Universitas STEKOM yang salah satu narasumbernya adalah seorang profesor dari Amerika Serikat. Narasumber tersebut adalah Kaushik Dutta yang merupakan seorang Professor dan School Director di Universitas Florida Selatan. Profesor Dutta dalam presentasinya menyampaikan materi tentang sistem pendukung keputusan yang merupakan produk IT yang sangat berguna dalam bisnis perusahaan.
Materi yang disampaikan oleh profesor Dutta meliputi Framework, Applications for Business, Techniques, dan Infrastructure. Karena materi yang disampaikan cukup panjang, artikel berita yang membahas tentang presentasi Profesor Dutta kita bagi menjadi beberapa bagian. Saat ini kita memasuki part ke 4. Jika pembaca ingin tahu presentasi sebelumnya, silahkan lihat beberapa part sebelumnya pada judul artikel yang sama.
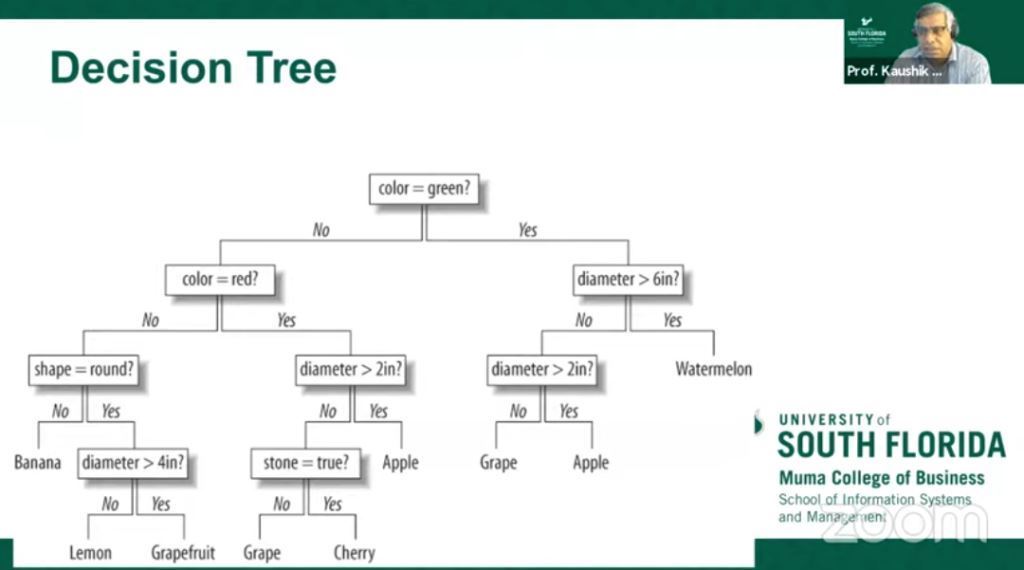
Bersambung dari part sebelum, selanjutnya Profesor Dutta menjelaskan tentang teknik dasar yang sering digunakan dalam analisis data, yaitu klasifikasi dan clustering. Menurutnya, dua hal tersebut berbeda.
Klasifikasi dan clustering adalah dua metode identifikasi pola yang digunakan dalam pembelajaran mesin. Meskipun kedua teknik memiliki kesamaan tertentu, perbedaannya terletak pada kenyataan bahwa klasifikasi menggunakan kelas yang telah ditentukan di mana objek ditugaskan, sementara clustering mengidentifikasi kesamaan antara objek, yang dikelompokkan sesuai dengan karakteristik yang sama dan yang membedakannya dari kelompok objek lain. Kelompok-kelompok ini dikenal sebagai "cluster". Dalam kasus Klasifikasi, ada label yang telah ditentukan sebelumnya yang ditetapkan untuk setiap instance input sesuai dengan propertinya sedangkan dalam pengelompokan label tersebut tidak ada.
Jika dirinci lebih detail, perbedaan klasifikasi data dan clustering data dapat dilihat seperti berikut :
- Klasifikasi digunakan untuk supervised learning sedangkan pengelompokan digunakan untuk unsupervised learning.
- Proses pengklasifikasian instance input berdasarkan label kelas yang sesuai dikenal sebagai klasifikasi sedangkan pengelompokan instance berdasarkan kesamaannya tanpa bantuan label kelas dikenal sebagai clustering.
- Karena Klasifikasi memiliki label, maka diperlukan dataset pelatihan dan pengujian untuk memverifikasi model yang dibuat tetapi tidak perlu pelatihan dan pengujian dataset dalam clustering.
- Klasifikasi lebih kompleks dibandingkan dengan clustering karena ada banyak tingkatan dalam fase klasifikasi sedangkan pada clustering hanya proses pengelompokan data.
- Contoh klasifikasinya adalah Logistic Regression, Naive Bayes Classifier, Support Vector Machines, dll. Sedangkan contoh clustering adalah algoritma clustering k-means, algoritma clustering Fuzzy c-means, algoritma clustering Gaussian (EM), dll.
Meskipun clustering dan klasifikasi memiliki kelebihan dan kekurangan masing-masing, namun keduanya bisa dimanfaatkan secara kolaboratif sesuai kasus yang sedang dihadapi. Jika kita telah secara jelas mengetahui label kelompok pada kumpulan data yang kita miliki, maka teknik klasifikasi akan sangat mudah kita terapkan. Namun jika pola dan label kelompoknya belum kita ketahui dengan pasti, maka clustering bisa menjadi pilihan yang lebih mudah dalam menganalisis data. Bahkan dalam kenyataannya, setelah kita melakukan clustering, kemudian kita mengenali pola-pola yang ada pada kumpulan data kita, maka kita bisa melakukan labelisasi dan klasifikasi terhadap data yang kita proses tersebut.
Clustering biasanya digunakan dalam proyek untuk perusahaan yang ingin menemukan aspek umum dalam pelanggan mereka untuk menerapkan segmentasi pelanggan, membuat peta perjalanan pelanggan atau menemukan grup dan memfokuskan produk atau layanan. Jadi, jika persentase pelanggan yang signifikan memiliki kesamaan aspek tertentu (usia, jenis keluarga, dll.), perusahaan dapat membenarkan kampanye, layanan, atau produk tertentu. Clustering juga berguna untuk memperoleh wawasan dan informasi umum.
Di sisi lain, klasifikasi termasuk dalam supervised learning, yang berarti bahwa kita mengetahui data input (diberi label dalam kasus ini) dan kita mengetahui kemungkinan output dari algoritma tersebut. Ada klasifikasi biner yang menanggapi masalah dengan jawaban kategoris (seperti "ya" dan "tidak", misalnya), dan multiklasifikasi, untuk masalah di mana kita menemukan lebih dari dua kelas, menanggapi jawaban yang lebih terbuka seperti "hebat ", "biasa" dan "tidak cukup".
Bersambung...
Belajar Keputusan Berbasis Data untuk Manajer di Perusahaan Gaya Baru bersama Profesor Dutta dari Amerika Serikat Part 5
Webinar International
Back to News
Webinar International
Monday, October 31, 2022
Priyadi, S.Kom, M.Kom
0 Views