
The development of information technology today is very helpful in the company's business. However, if we do not understand the type of technology needed, we will choose the wrong technology. Especially in the field of decision making for companies, there is one information technology product that is very helpful, namely a decision support system.
STEKOM university's efforts to have a global reach include holding webinars on an international scale. On this occasion we will discuss an international webinar held by STEKOM University in which one of the speakers is a professor from the United States. The resource person is Kaushik Dutta who is a Professor and School Director at the University of South Florida. Professor Dutta in his presentation delivered material on decision support systems which are IT products that are very useful in corporate business.
The material presented by Professor Dutta includes Framework, Applications for Business, Techniques, and Infrastructure. Because the material presented is quite long, the news article discusses our Professor Dutta's presentation for several parts. We are now entering the fifth part. If the reader wants to know the previous presentation, please see the previous chapters on the same article title.
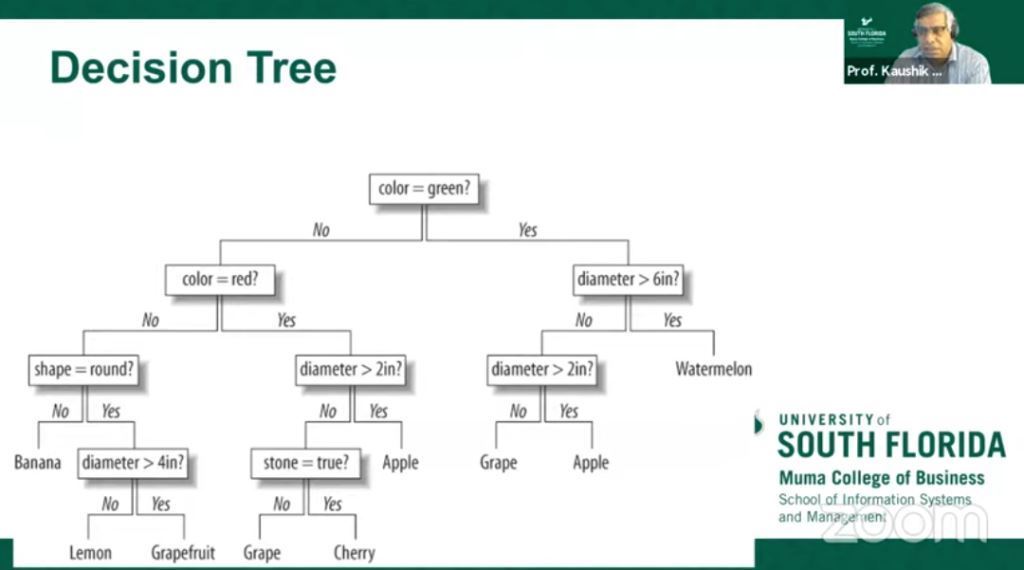
Continuing from the previous section, Professor Dutta then explained about the basic techniques that are often used in data analysis, namely classification and grouping. According to him, prayer is different.
Classification and clustering are two ways of knowing the patterns used in machine learning. Although the two have certain similarities, the difference lies in the fact that classification uses a predefined class to which objects are assigned, while grouping, the similarity between objects, corresponds to the same characteristics and distinguishes them from other groups of objects. These groups are known as "clusters". In case of Classification, there is a predefined label assigned to each input instance according to its properties whereas in grouping there is none.
In more detail, the differences in data classification and data clustering can be seen as follows:
- while Classification is used for guided learning and grouping is used for unsupervised learning.
- The process of classifying input instances based on class labels is known as classification while grouping instances based on their similarities without the help of class labels is known as clustering.
- Because Classification has a label, training and testing datasets are needed to verify the model created but no training and testing of datasets in clustering are needed.
- Classification is more complex than grouping because there are many levels in the classification phase, whereas grouping is only the process of grouping data.
- Examples of classifications are Logistic Regression, Naive Bayes Classifier, Support Vector Machines, etc. While the examples of clustering are k-means clustering algorithm, Fuzzy c-means clustering algorithm, Gaussian (EM) clustering algorithm, etc.
Although grouping and classification have their respective advantages and disadvantages, they can be used collaboratively according to the case at hand. If we clearly know the group label in the data set that we have, then the classification will be very easy for us to have. However, if we do not know the pattern and label of the group for sure, then clustering can be an easier choice in analyzing the data. In fact, after we do clustering, then we recognize the patterns that exist in our data set, then we can label and classify the data that we process.
Grouping is commonly used in projects for companies that want to find common aspects in their customers to implement customer segmentation, create travel maps or find groups and focus on products or services. So, if a significant percentage of customers share certain aspects in common (age, family type, etc.), the company can justify, certain services, or products. Grouping is also useful for gaining general insight and information.
On the other hand, classification belongs to supervised learning, which means that we know the input data (labeled in this case) and we know the possible outputs of the algorithm. There is binary classification which responds to problems with categorical answers (such as "yes" and "no", for example), and multiclassification, for problems where we find more than two classes, responding to more open-ended answers such as "great", "ordinary" and "not enough".
Continued....
STEKOM university's efforts to have a global reach include holding webinars on an international scale. On this occasion we will discuss an international webinar held by STEKOM University in which one of the speakers is a professor from the United States. The resource person is Kaushik Dutta who is a Professor and School Director at the University of South Florida. Professor Dutta in his presentation delivered material on decision support systems which are IT products that are very useful in corporate business.
The material presented by Professor Dutta includes Framework, Applications for Business, Techniques, and Infrastructure. Because the material presented is quite long, the news article discusses our Professor Dutta's presentation for several parts. We are now entering the fifth part. If the reader wants to know the previous presentation, please see the previous chapters on the same article title.
Continuing from the previous section, Professor Dutta then explained about the basic techniques that are often used in data analysis, namely classification and grouping. According to him, prayer is different.
Classification and clustering are two ways of knowing the patterns used in machine learning. Although the two have certain similarities, the difference lies in the fact that classification uses a predefined class to which objects are assigned, while grouping, the similarity between objects, corresponds to the same characteristics and distinguishes them from other groups of objects. These groups are known as "clusters". In case of Classification, there is a predefined label assigned to each input instance according to its properties whereas in grouping there is none.
In more detail, the differences in data classification and data clustering can be seen as follows:
- while Classification is used for guided learning and grouping is used for unsupervised learning.
- The process of classifying input instances based on class labels is known as classification while grouping instances based on their similarities without the help of class labels is known as clustering.
- Because Classification has a label, training and testing datasets are needed to verify the model created but no training and testing of datasets in clustering are needed.
- Classification is more complex than grouping because there are many levels in the classification phase, whereas grouping is only the process of grouping data.
- Examples of classifications are Logistic Regression, Naive Bayes Classifier, Support Vector Machines, etc. While the examples of clustering are k-means clustering algorithm, Fuzzy c-means clustering algorithm, Gaussian (EM) clustering algorithm, etc.
Although grouping and classification have their respective advantages and disadvantages, they can be used collaboratively according to the case at hand. If we clearly know the group label in the data set that we have, then the classification will be very easy for us to have. However, if we do not know the pattern and label of the group for sure, then clustering can be an easier choice in analyzing the data. In fact, after we do clustering, then we recognize the patterns that exist in our data set, then we can label and classify the data that we process.
Grouping is commonly used in projects for companies that want to find common aspects in their customers to implement customer segmentation, create travel maps or find groups and focus on products or services. So, if a significant percentage of customers share certain aspects in common (age, family type, etc.), the company can justify, certain services, or products. Grouping is also useful for gaining general insight and information.
On the other hand, classification belongs to supervised learning, which means that we know the input data (labeled in this case) and we know the possible outputs of the algorithm. There is binary classification which responds to problems with categorical answers (such as "yes" and "no", for example), and multiclassification, for problems where we find more than two classes, responding to more open-ended answers such as "great", "ordinary" and "not enough".
Continued....